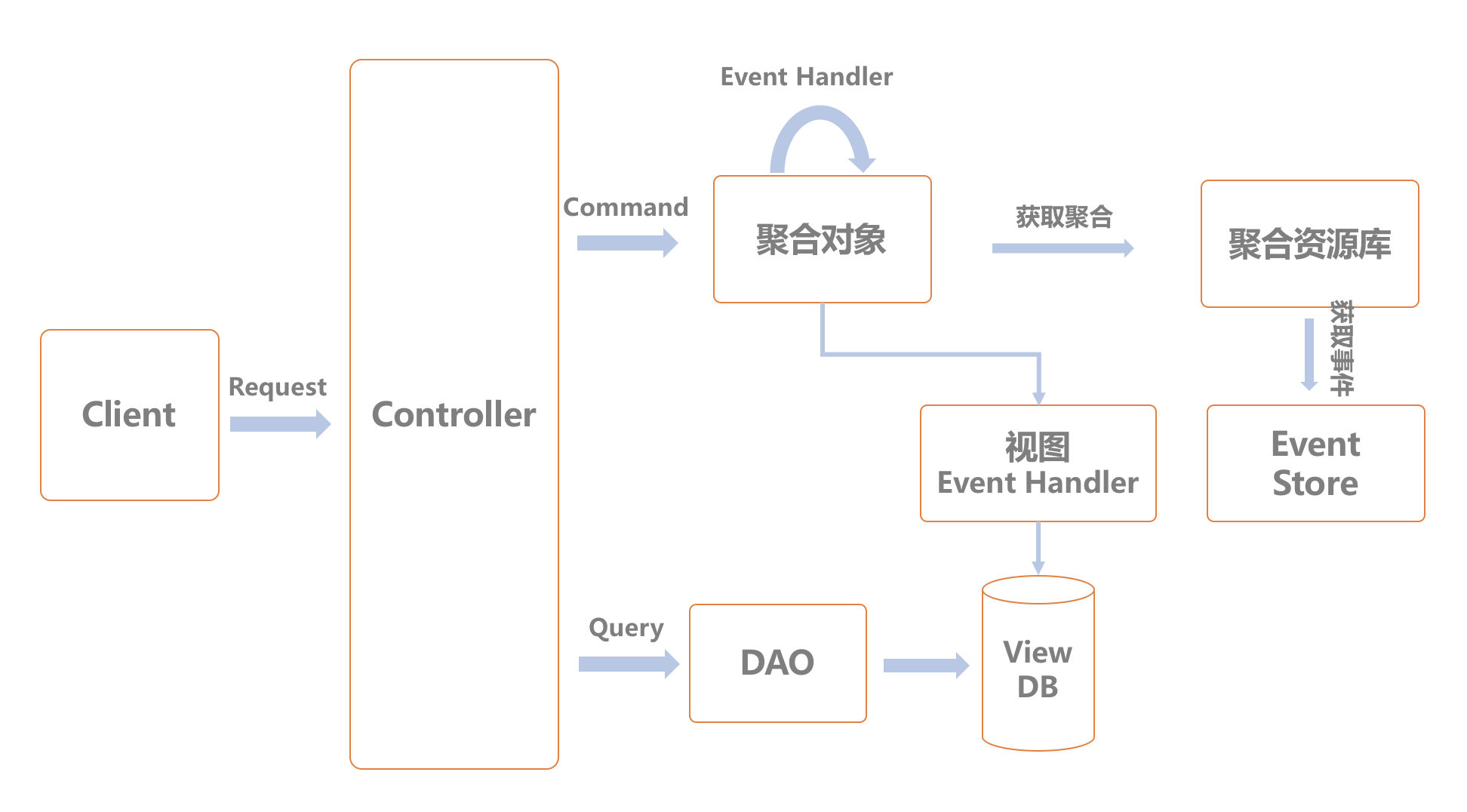
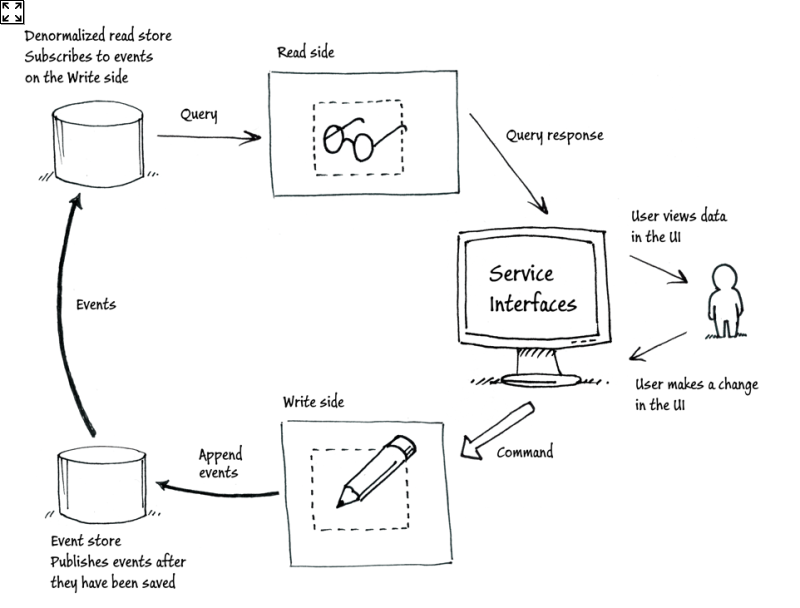
REST 架构风格具有定义明确的约束,可帮助开发者写出可扩展的 Web 服务接口, 但是 APIs 并不容易定义。这就是为什么我归纳了这些问题和解决方案。
资源和基本操作
列表和分页
多对多关系
字段过滤
长时间运行的操作
并发处理
版本控制
资源整合聚合
多语言
资源和基本操作 REST API 完全是与资源相关的交互操作。客户端可以通过 API 创建、替换、更新、删除或者获取资源。所有的这些操作都和 HTTP 动作有明确的映射。user 资源,客户端可以通过以下端点与之交互
1 2 3 4 5 6 7 8 9 10 11 12 13 14 // 创建一个资源 POST /users // 通过资源的唯一标识,获取资源的详细信息 GET /users/:id // 部分更新给定 ID 标识资源的内容 PATCH /users/:Id // 替换(全量更新)给定 ID 标识资源的内容 PUT /users/:id // 删除给定 ID 标识的资源 DELETE /users/:id
创建一个新用户
1 2 3 4 5 6 7 POST /users HTTP/1.1 Host: example.com Content-Type: application/json { "name": "bob", "age": 76 }
根据资源 ID 标识获取用户信息
1 2 GET /users/8646291 HTTP/1.1 Host: example.com
部分更新用户信息:
1 2 3 4 5 6 PATCH /users/8646291 HTTP/1.1 Host: example.com Content-Type: application/json { "name": "bob-update" }
PATCH 请求是对资源的部分更新,所以上述的例子,属性 age 将保持原来的值,仅仅名称发生了变化。PATCH ,可以使用 POST 。但是不要用 PUT, HTTP 定义 PUT 用于全量更新或替换资源[RFC7231 ]。
1 2 3 4 5 6 PUT /users/8646291 HTTP/1.1 Host: example.com Content-Type: application/json { "age": 54 }
如果使用如上请求更新用户的age,用户的 name 信息将丢失,因为 PUT 请求是全量更新的。
删除资源:
1 2 DELETE /users/8646291 HTTP/1.1 Host: example.com
列表和分页 客户端能够使用 GET 请求和顾虑条件获取大量数据。必须对结果进行分页,最常用的分页是基于游标的分页和基于偏移量的分页。每个分页请求都有限制参数,用于限制分页大小。
基于游标的分页 也许你也会看到它叫基于键集的分页,这是大的数据集分页中最有效的方法,因为性能要比基于偏移量的分页更好。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # REQUEST GET /users?limit=100 HTTP/1.1 Host: example.com # RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 { "items": [ { "id": 123, "meta":{ "cursor": "js3Hsji3nj" } }, // other items ... { "id": 426, "meta":{ "cursor": "ke3Gdk1xyi" } } ] }
如你所看到的,每个元素都有一个 meta.cursor 属性,该游标是一个随机的字符串,用于标记元素列表中的特定元素,可用于检索下一个或上一个元素,并将其作为 after 或 before 参数。after 存在,则返回的该游标作为第一个元素之后的元素。如果该游标之后没有元素,则返回的集合必须为空。如果存在 before,则返回该游标作为最后一个元素之前的元素。客户端可以提交如下请求用来检索之前、之后的元素
1 2 3 4 5 6 7 8 9 # 获取之前的元素 GET /users?after=ke3Gdk1xyi&limit=100 HTTP/1.1 Host: example.com # 获取之后的元素 GET /users?before=js3Hsji3nj&limit=100 HTTP/1.1 Host: example.com # 获取之前的元素 GET /users?after=ke3Gdk1xyi&before=js3Hsji3nj&limit=100 HTTP/1.1 Host: example.com
基于偏移量的分页 基于偏移的分页,允许客户端跳转到特定页面,但是在大多数情况下,在处理非常大的数据集时性能会较差,但是它的知名度更高。
1 2 3 4 5 6 7 8 9 10 11 12 # REQUEST GET /users?limit=100 HTTP/1.1 Host: example.com # RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 { "items": [ // the results ] }
获取下一个分页,必须增加 skip 查询参数
1 2 3 4 5 6 // 获取第二页 GET /users?skip=100&limit=100 HTTP/1.1 Host: example.com // 获取第三页 GET /users?skip=200&limit=100 HTTP/1.1 Host: example.com
页面引用 我们可以使用页面引用来简化分页操作,它提供指向页面的指针,也就是说标记特点页面的游标。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # REQUEST GET /users?limit=100 HTTP/1.1 Host: example.com # RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 { "items": [ // the results ], "paging": { "prev": "kewIJbwDS2Bsja...", "next": "dFRdkdek2KLmcd..." } }
补充说明一下,GitHub 的分页 API,分页返回的结果是在 Header 中的 Link 标签中。
1 2 3 4 5 6 7 8 9 10 11 12 13 # REQUEST GET https://api.github.com/organizations/317776/repos?type=all&size=2&page=4 Host: api.github.com # RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Link: <https://api.github.com/organizations/317776/repos?type=all&size=2&page=3>; rel="prev", <https://api.github.com/organizations/317776/repos?type=all&size=2&page=5>; rel="next", <https://api.github.com/organizations/317776/repos?type=all&size=2&page=7>; rel="last", <https://api.github.com/organizations/317776/repos?type=all&size=2&page=1>; rel="first" { "items": [ // the results ] }
page.next 是客户端用于请求下一批数据集的页面引用, pageing.prev 是客户端用于请求上一批数据集的页面引用:
1 2 GET /users?page_ref=dFRdkdek2KLmcd&limit=100 HTTP/1.1 Host: example.com
在第一个请求之后,limit 参数是 URL 中除 page_ref 的唯一参数,因为这样可以保护两次请求之间的限制条件被篡改。防止破坏请求参数(例如排序和筛选条件)直接嵌入到 page_ref 中以某种方式存储。尝试添加或修改过滤条件将导致请求失败。如果需要其他顺序或筛选条件,则必须在第一页上重新开始。还需要注意的是,页面引用通常是临时的不需要保存。
多对多关系 有些时候两个资源之间需要创建多对多关系,你可以创建一个新的资源代表这个关系,让我们看如下的例子:学生-课程-评价 资源。
1 2 3 4 5 6 // 增加一个 学生-课程-评价 关系 POST /student-course-rates // 列出所有的学生-课程的评价,根据学生或者课程过滤 GET /student-course-rates // 根据ID删除评价 DELETE /student-course-rates/:id
一个学生可以增加一个课程的评价:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # REQUEST POST /student-course-rates HTTP/1.1 Host: example.com Content-Type: application/json { "studentId": "3298wdi28dh28wid92", "courseId": "93710949600282", "rate": 10 } # RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 { "id": 1239836164989016, "student": { "id": "3298wdi28dh28wid92", "age": 18 }, "course": { "id": "93710949600282", "description": "..." }, "rate": 10 }
获取课程所有的评价:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # REQUEST GET /student-course-rates?course=93710949600282&limit=10 HTTP/1.1 Host: example.com # RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 { "items": [ { "id": 1239836164989016, "student": { "id": "[email protected] ", "age": 18 }, "course": { "id": "93710949600282", "description": "..." }, "rate": 10 }, // other results ... ] }
我们看到,一个 学生-课程-评价 资源具有一个标识符,即属性id,并使用关联对(studentId,courseId),这样可以通过查询参数删除过滤删除。 DELETE /student-course-rates?course=xxx&student=xxx
字段筛选 有时候由于性能原因,客户端需要选择应在响应中包括哪些属性,即要求查询参数字段包含用逗号分隔的属性列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # REQUEST GET /users/12fw342ej1 HTTP/1.1 Host: example.com #RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 { "id": "12fw342ej1", "name": { "familyName": "Muro", "givenName": "Rupert" }, "age": 67 }
客户端定义返回的参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 # REQUEST GET /users/12fw342ej1?fields=name.familyName%2Cage HTTP/1.1 Host: example.com #RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 { "name": { "familyName": "Muro" }, "age": 67 }
我们还可以将字段的子集映射成预定义的 style,这样客户端可以选择 style 来返回需要的预定义的字段。id、name.familyName 和 age 映射到 compact style ,将 id、name.familyName、name.givenName 和 age 映射到 complete style,查询时候使用不同的 style 即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 # REQUEST the compact style GET /users/12fw342ej1?style=compact HTTP/1.1 Host: example.com # RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 { "id": "12fw342ej1", "name": { "familyName": "Muro" }, "age": 67 } # REQUEST the complete style GET /users/12fw342ej1?style=complete HTTP/1.1 Host: example.com # RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 { "id": "12fw342ej1", "name": { "familyName": "Muro", "givenName": "Rupert" }, "age": 67 }
长时间运行的操作 为了提高可伸缩性并简化部署,Web服务响应时间必须尽可能短,但是有时我们需要计算长时间运行的操作,我们该怎么做?GET 请求时,根据操作的当前状态进行如下响应:
操作仍在运行:返回状态代码 200(Ok),并表示操作状态。
操作结束并成功:返回状态码 303(See Other)和 Location header,其中包含创建的资源的 URI。
操作结束并失败:返回态码 200(Ok) ,并提供有关失败的信息。
让我们看一个例子,设计一个从 URI 提取摘要的 Web 服务,我们有两种资源,摘要和提取任务:
1 2 3 4 5 6 7 8 // 根据 ID 获取摘要信息 GET /summary/:id // 创建一个需要长时间运行获取摘要的任务 POST /extraction-task // 更加ID返回任务信息 GET /extraction-task/:id
客户端可以使用 POST 请求创建新的提取任务,服务器返回状态码 202(Accepted),并返回任务相关的信息(例如: 客户端下一次检查任务的时间 checkAfter ) 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # REQUEST POST /extraction-task HTTP/1.1 Host: example.com Content-Type: application/json { "from": { "uri": "https://extract.from.here.com" } } # RESPONSE HTTP/1.1 202 Accepted Content-Type: application/json;charset=UTF-8 Content-Location: https://example.com/extraction-task/348wd39 { "id": 348wd39, "state": "pending", "checkAfter": "2019-01-10T22:32:12Z", "info": { "from": { "uri": "https://extract.from.here.com" } } }
然后,客户端可以使用 GET 请求查询任务状态,如果服务端仍在处理该任务,它将返回:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # REQUEST GET /extraction-task/348wd39 HTTP/1.1 Host: example.com # RESPONSE HTTP/1.1 202 Accepted Content-Type: application/json;charset=UTF-8 { "id": 348wd39, "state": "pending", "checkAfter": "2019-01-10T22:32:12Z", "info": { "from": { "uri": "https://extract.from.here.com" } } }
服务器成功完成操作后,将返回 303(See Other),这意味着可以使用 GET 方法在另一个 URI 获取结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # REQUEST GET /extraction-task/348wd39 HTTP/1.1 Host: example.com # RESPONSE HTTP/1.1 303 See Other Location: https://example.com/summary/239rfh392 Content-Location: https://example.com/extraction-task/348wd39 { "id": 348wd39, "state": "completed", "info": { "from": { "uri": "https://extract.from.here.com" } }, "finishDate": "2019-01-10T22:35:11Z" }
如果任务已经失败:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # REQUEST GET /extraction-task/348wd39 HTTP/1.1 Host: example.com # RESPONSE HTTP/1.1 200 OK Location: https://example.com/summary/239rfh392 Content-Location: https://example.com/extraction-task/348wd39 { "id": 348wd39, "state": "failed", "info": { "from": { "uri": "https://extract.from.here.com" } }, "finishDate": "2019-01-10T22:35:11Z", "detail": "The URI doesn't exist (status code 404)." }
如果您希望使用回调的方式,则只需在操作创建过程中给定一个 URI,操作结束时便会使用该 URI 通知客户端:
1 2 3 4 5 6 7 8 9 10 # REQUEST POST /extraction-task HTTP/1.1 Host: example.com Content-Type: application/json { "from": { "uri": "https://extract.from.here.com" }, "notifyOn": "https://client.com" }
并发处理 一台服务器可以同时为多个客户端提供服务,这增加了出现并发问题的可能。例如,两个客户端使用 PUT 或 POST 同时修改同一个资源。 该解决方案来自(RFC7232 )。header 中包含 Last-Modified 和 ETag 一个或两个条件。header 中包含 If-Unmodified-Since 和 If-Match 中的一个或两个。
让我们来看一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # REQUEST GET /users/12fw342ej1 HTTP/1.1 Host: example.com # RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 ETag: "abcec491d0a4e8ecb8e14ff920622b9c" Last-Modified: Sun, 05 Jan 2019 14:14:52 GMT { "id": "12fw342ej1", "name": { "familyName": "Muro", "givenName": "Rupert" }, "age": 67 }
为了符合条件请求,客户端必须在 header 包含 If-Unmodified-Since 和 If-Match 中的一个或两个。 如果没有任何内容,则服务端将在响应正文中以 403(Forbidden) 进行回复。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # REQUEST PUT /users/8646291 HTTP/1.1 Host: example.com Content-Type: application/json { "age": 54 } # RESPONSE HTTP/1.1 403 Forbidden Content-Type: application/json;charset=UTF-8 { "code": "120", "message": "The conditional headers are required; If-Unmodified-Since and/or If-Match" }
如果匹配到更新的资源,它可以处理更新并返回 200(OK) 或 204(No Content)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # REQUEST PUT /users/8646291 HTTP/1.1 Host: example.com If-Unmodified-Since: Sun, 05 Jan 2019 14:14:52 GMT If-Match: "abcec491d0a4e8ecb8e14ff920622b9c" Content-Type: application/json { "age": 54 } # RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 ETag: "1e0e5a0fb102db75aa36d4356936fe4c" Last-Modified: Sun, 05 Jan 2019 14:15:02 GMT { "id": "8646291", "age": 54 }
如果不是,则服务端必须返回状态代码 412(Precondition Failed),并说明原因。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # REQUEST PUT /users/8646291 HTTP/1.1 Host: example.com If-Unmodified-Since: Sun, 05 Jan 2019 13:14:52 GMT If-Match: "b1b3833b514f4b4a5207b572405e786f" Content-Type: application/json { "age": 54 } # RESPONSE HTTP/1.1 402 Precondition Failed Content-Type: application/json;charset=UTF-8 { "code": "121", "message": "The provided conditional headers doesn't match current values; The request rely on stale informations" }
版本控制 有时我们需要对 API 进行版本控制,因为提供不同的版本会极大地提高对 API 的理解和维护。header 的 Accept 和 Content-Type 进行版本控制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 # REQUEST VERSION 1 GET /users/12fw342ej1 HTTP/1.1 Host: example.com Accept: application/json;version=1 # RESPONSE VERSION 1 HTTP/1.1 200 OK Content-Type: application/json;version=1;charset=UTF-8 { "id": "12fw342ej1", "familyName": "Muro", "givenName": "Rupert" "age": 67 } # REQUEST VERSION 2 GET /users/12fw342ej1 HTTP/1.1 Host: example.com Accept: application/json;version=2 # RESPONSE VERSION 2 HTTP/1.1 200 OK Content-Type: application/json;version=2;charset=UTF-8 { "id": "12fw342ej1", "name": { "familyName": "Muro", "givenName": "Rupert" }, "age": 67 }
资源聚合(门面模式) 有时需要在从同一地方获取多个资源,客户端必须调用多个接口,然后组合所需资源并展示。
举个例子,我们需要在一个页面来显示用户的财务状况,该页面需要显示,用户信息、前10个投资、后10个银行记录、总余额、信用卡限额。如果分别请求每个资源都会导致性能问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # REQUIRE EACH REQUEST GET /users/12fw342ej1 HTTP/1.1 Host: example.com Accept: application/json GET /investiments?user=12fw342ej1 HTTP/1.1 Host: example.com Accept: application/json GET /bank-records?user=12fw342ej1 HTTP/1.1 Host: example.com Accept: application/json GET /credit-card?user=12fw342ej1 HTTP/1.1 Host: example.com Accept: application/json GET /bank-account/ew239wqw21ui32une HTTP/1.1 Host: example.com Accept: application/json
为了解决该问题,我们可以创建一个汇总结果的资源,称为财务报告,并且由于它与用户关联,因此可以作为用户的子资源:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # REQUIRE EACH REQUEST GET /users/12fw342ej1/financial-report HTTP/1.1 Host: example.com Accept: application/json # RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 { "userInfo": { .. }, "lastInvestiments": [...], "lastBankRecords": [...], "bankAccount": 12321, "creditCartLimits": {...} }
多语言 HTTP 提供了两个用于语言协商的 header 用来处理语言。客户端提供 Accept-Language ,用来通知服务器有关首选语言的信息,Content-Language 由服务端在响应中提供。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 # REQUEST GET /products/782hb1yufhd8923 HTTP/1.1 Host: example.com Accept-Language: en,en-US,it Accept: application/json # RESPONSE HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Content-Language: en Vary: Accept-Language { "id": "782hb1yufhd8923", "description": { "localizedValue": "This is a description", "translations": [ { "lang": "en", "value": "This is a description" }, { "lang": "it", "value": "..." } ] } }
参考 RESTful API Patterns
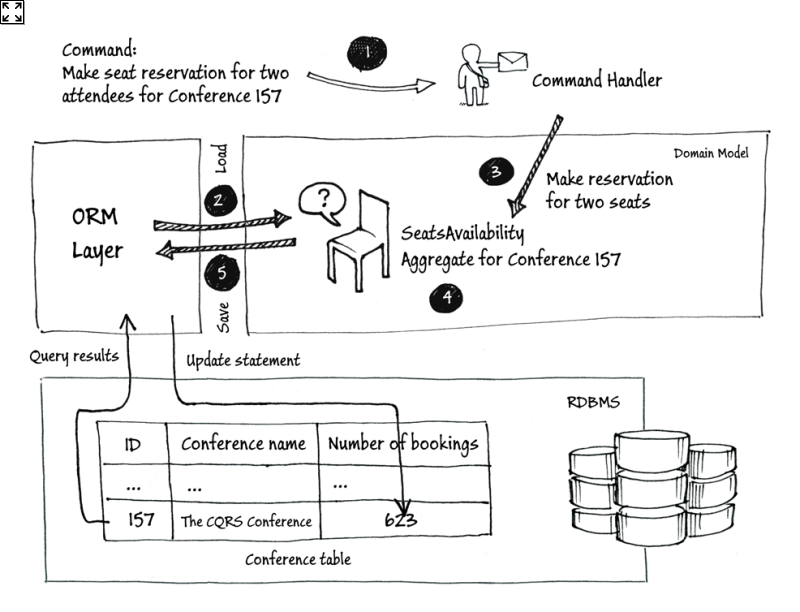
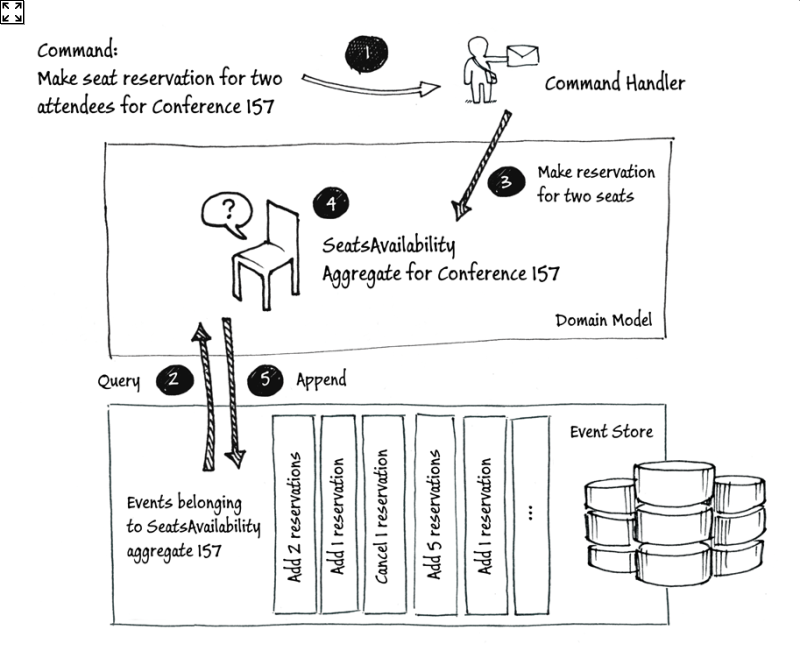 使用事件溯源代替 ORM 层和关系数据库(RDBMS),执行步骤:
使用事件溯源代替 ORM 层和关系数据库(RDBMS),执行步骤: