Akka学习之路
我属于Akka的初学者,本文分享了我在Akka学习和项目实战的一些经验,以及总结和反思,希望对Akka的初学者有所帮助或启发。
初识Akka
还是3年前,2016年我司刚成立研发部,我们打算基于一个开源项目 Kaa来打造自己的IoT PaaS平台。 这是我第一次在工作中阅读、研究、修改大型开源项目,让我受益匪浅,非常感谢这次个工作经历。没错,Kaa这个开源项目正是用了Akka框架、Actor编程模式来实现其业务的。
Kaa只用了Akka的一些基本特性,源码中用到最多的方法就是 Actor.tell()发送消息。再高级一点的,创建Actor的时候用到了RoundRobinPool 路由轮询特性;SupervisorStrategy 来针对Actor定制异常处理策略;Broadcast 消息广播特性;schedule 定时器。最值得借鉴的是Kaa为Akka和Spring的基础提供了范例。可以阅读如下有代表性的源代码:DefaultAkkaService, LocalEndpointActor, LocalEndpointActorMessageProcessor。
今天回头看看Kaa这个项目,并没有把Akka框架用到位:
- Kaa的集群和负载均衡完全是自己实现的,而且实现的比较复杂。每个集群节点都持有了所有Endpoint,大家会发现有
LocalEndpointActor– 本地终端Actor,用来处理终端各种业务消息的Actor,和GlobalEndpointActor– 远程终端Actor,用来转发消息到其真正的节点上。当集群节点收到消息,发现终端不在当前节点上,会根据GlobalEndpointActor中记录的终端所在集群的实际地址,把消息转发到其真正所在的服务节点LocalEndpointActor上。有兴趣的同学可以从 DefaultLoadBalancingService.onStatusUpdate 类为入口看看负载均衡是如何实现的。 - Actor处理的消息没有进行分类(分策略),这会导致消息业务处理类非常复杂,大家可以看看上文提到的
LocalEndpointActorMessageProcessor。对终端所有的消息处理都交织在该类里面,并没有从业务上对消息进行分类,这会使该类随着消息类型越来越多,导致代码行数越来越长,最终代码难以维护。 - 消息流处理节点太多, Actor有祖父关系,这个关系是根据资源归属来划分的。例:终端上报Log到Kaa平台,首先Log消息会经过
EncDecActor进行消息编解码, 然后一层层转发OperationServerActor->TenantActor->ApplicationActor->EndpointActor。终端归属于某个应用,应用归属于某个租户,租户在OperationServer上,OperationServer起到了负载均衡、故障转移的作用。父Actor中会创建一个Map,聚合了所有子Actor,虽然方便转发,但是一条消息处理的节点太多,消息流太长。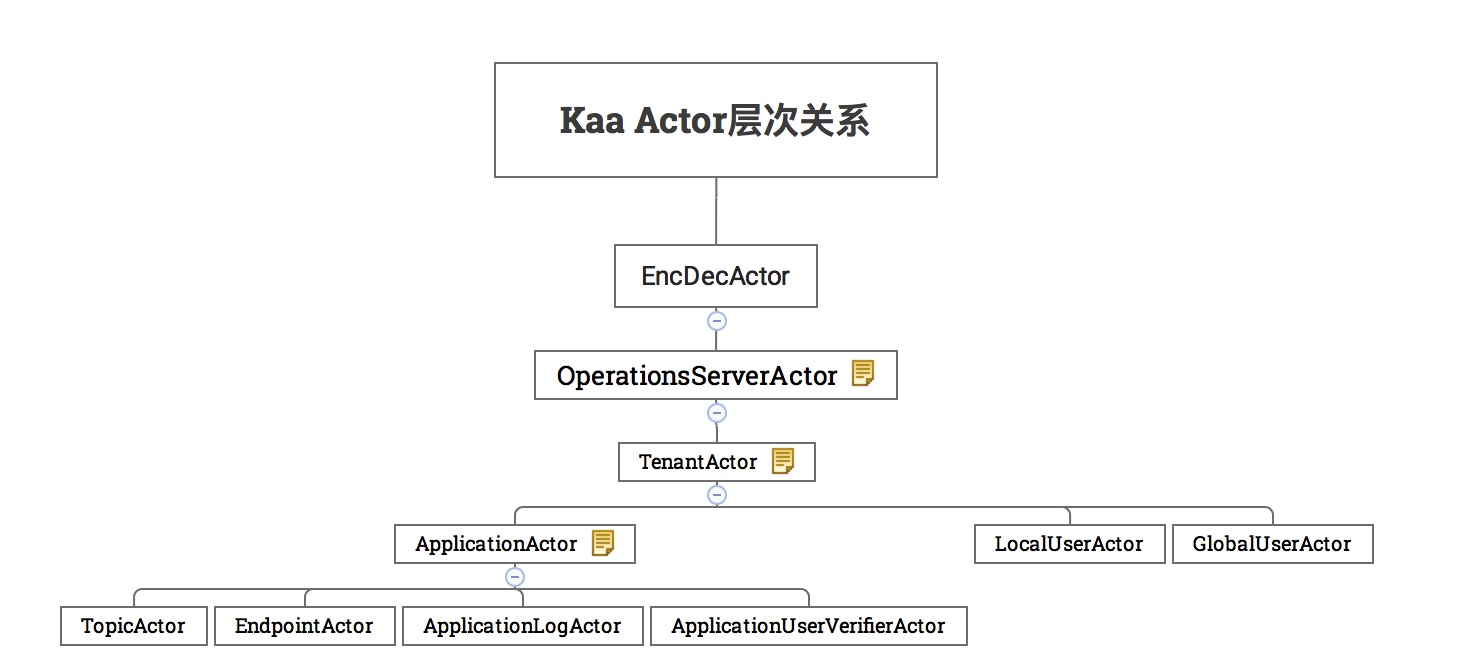
Akka 项目实战
Kaa定制开发不到半年,应该是从2016年6月左右就转战到公司成立的新项目-全球IoT连接管理平台,如今的ACell产品研发中。从此,Akka的学习就告一段落,直到2018年年初,ACell为满足设备(SIM卡)在VPDN场景下的高性能、高并发的在线计费需求。ACell需要对架构上的调整优化,其中我负责了在线计费功能的研发。这个版本时间非常紧张,分析了需求场景后,觉得用Akka实现起来非常合适,于是在巨大压力下大胆使用了Akka。这里要感谢公司小伙伴对我的信任。
当时想用Akka主要有如下几点考虑:
- 由于单个Actor总是线程安全的,为每个设备创建一个Actor,高并发场景下,不需要考虑并发更新问题。
- 设备的计费域模型中,涉及非常多的、动态的域值对象,Actor可以将这些信息(状态)放在内存中,避免依赖外部存储,防止因IO操作导致性能问题。
- Actor位置透明,Akka天生支持分布式, 方便后期系统水平扩展。
- 之前接触过Akka,有一定的知识储备, 虽然有风险,但还可控。
虽然一年多前对Akka有些许了解,但是并没有实际的项目经验。当时为了让心理有对Akka增加些许底气,快速的把《Akka入门与实践》读完,又补充阅读了官方文档中关于Actor Persistence,和Akka-cluster的内容,然后就开始付诸实践了。在实际开发过程中,有Kaa项目作为参考,并没有遇到阻塞性问题,而且版本上线后也没有遇到大的问题。
Akka 踩坑、进阶
版本上线后不久,有幸在GitHub上遇到了Eclipse Ditto。他是我遇到的Java技术栈里运用Akka最棒的开源IoT项目,Akka的各种特性运用的淋漓尽致,简直是Akka的最佳实践。
接下来就学习吸收Ditto的各种最佳实践, 对ACell进行重构优化。还记得上面说的Kaa的几个问题ACell也同时存在吗?
- Akka-cluster 很好的解决了集群问题。Ditto之前版本有专门的Akka Cluster工具包,现在的新版本改用了Akka Management管理Akka集群,代码量虽然少了但是功能更强大了。目前ACell运用了Cluster Singleton做到了主备模式,还没用到Cluster Sharding,因为支持集群分片,要对Actor的消息进行改造,还没有落实。
- 根据不同业务含义的消息,对消息分策略处理,可以参看 ThingPersistenceActor。 使用策略模式会使代码结构非常清晰,尤其当Actor使用了Become/Unbecome,策略模式能够有效避免代码混乱。
- Ditto中Actor层次结构只有两层,没有消息的层层转发。以Thing Actor为例,
ThingSupervisorActor负责创建和监管ThingPersistenceActor,并转发业务消息给子Actor,当发现子Actor异常终止,以指数退避的方式再次唤起子Actor。ThingPersistenceActor作为子Actor接收处理各种转发来的业务消息即可,层次结构非常简单。目前ACell的Actor是根据资源归属来层层创建的,这种主父结构,虽然方便了Actor的查找定位以及消息广播,但是转发消息的样板代码太多,可以用 Distributed Publish Subscribe in Cluster 发布/订阅模式来代替。
在项目中踩过的坑:
- Actor的业务实现中,对有IO的操作的业务最好分离出去。可以创建单独的Actor或者异步发送消息交由外部容器处理,这样可以大大提升性能。
- 为不同业务含义的Actor专门创建不同的调度线程(Actor dispatcher)。如果创建Actor不指定dispatcher,会使用默认的
Default dispatcher,其线程配置是fork-join-executor方式。当你的Actor继承了AbstractPersistentActor,并且Actor数量非常多时,压测中会发现,系统吞吐量达到峰值,CPU利用却率不高,并且出现持久化超时Actor熔断现象。 - 使用PersistentActor,需要对Akka中的事件溯源模式(Event Sourcing)有一定的了解。否则你可能无法理解,如果消息没有使用persist()持久化, 就算是Actor状态有变化,使用saveSnapshot()保存快照也是无法生效的。
- Akka官方提供的Actor持久化插件是基于LevelDB的,它不支持分布式。但是社区有其他的开源插件,推荐使用 Akka Persistence Redis Plugin,因为之前使用过akka-persistence-jdbc,他会导致Akka的处理性能阻塞在数据库的性能上。
- 对具有持久化的Actor,需要在收到快照保存成功的消息之后,再做对快照数据做物化视图同步。防止因为快照保存失败,Actor重启后,journal消息再次消费,可能会导致物化视图数据和快照数据不一致现象。
总结、反思和计划
- 目前我对Akka还是仅仅停留在用的表面,没有真正深刻理解Akka的灵魂 – ‘反应式’设计模式,对Akka的设计思想还是一知半解。计划阅读今年刚上市的一本新书《反应式设计模式》。
- Akka还有很多非常实用的特性并没有了解,一些最佳实践并没有掌握。继续阅读官方文档和Ditto项目,根据不同特性编写小demo。
- Akka是用Scala编写的,有些时候需要对Akka源码的阅读,会有语言障碍,没法做到得心应手,只能边猜边看,后面需要系统的学习scala。
Akka初学者学习建议
有过学习Akka的朋友可能会发现,关于Akka无论是中文的还是英文的书籍实在太少了。最好的文档就是官方文档,有理论、有说明、有完整例子(java版、scala版),就是内容太多。我有如下几点建议:
- 对于Akka的初学者,可以先读一读《Akka入门与实践》和 《Akka应用模式:分布式应用程序设计实践指南》,前者偏入门、实战,后者偏设计、理论。这个两本书都很薄,200页不到,读起来不费劲。
- 有了上面积累的基础知识,阅读官方文档可以根据不同特性有针对性的阅读,配合写一些小demo,或阅读官方demo源码,加深印象。
- 阅读Eclipse Ditto源码,汲取项目经验,总结最佳实践。
- 深入理解Akka的设计思想,阅读《反应式设计模式》。这本书从作者到译者都是Akka源码的贡献者,书的内容质量没的说。